Introduction
A few years ago Microsoft saw the growth in requirements for processing big data and decided to create a new hardware / software based platform to fill that need.
They were to deliver an MPP enabled version of SQL Server and their hardware partner (initially HP) were to deliver the supporting hardware.
Microsoft Parallel Data Warehouse (PDW) was launched in 2011 and later rebranded as Microsoft Analytics Platform System (APS) - the PDW name was kept to refer to MPP version of SQL Server.
Architecture
As you can see below PDW has a control node and multiple compute nodes.
PDW is designed, of course, for horizontal scaling and data is spread across the different compute notes - think of the data as being partitioned.
PDW can support up to forty compute nodes each has it's own CPU memory and storage and the nodes are commodity servers i.e. relatively cheap.
I've used PDW on a data warehousing project. Massive volumes of data were loaded on a daily basis into PDW via it's landing stage in the UK from a Teradata instance in the US.
ETL processes then loaded the data into a Fact / Dimension data warehouse and finally the data was loaded into an SSAS Cube (outside PDW) to allow analysis of the data using tools such as Tableau.
Here's the typical architecture for PDW:
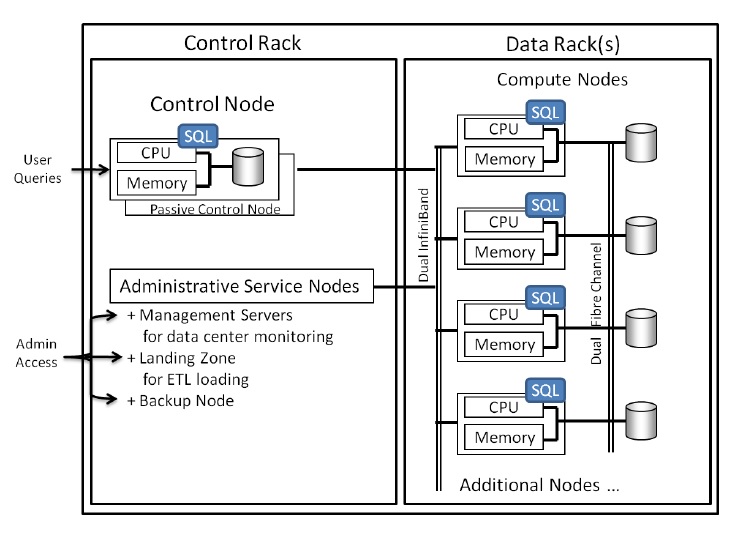
The diagram doesn't illustrate redundancy PDW supports failover, redundancy, uses RAID 1 etc..
A query (including inserts/upserts/deletes) coming into PDW will be examined by the control node and a request(s) sent to the relevant compute node(s).
This illustrates that if you can organise your data such that the majority of your queries only hit one compute node performance will be greatly enhanced.
This organisation of data is supported by PDW via partitioning and replication:
- Partitioning is the distribution of data across compute nodes - typically used in a data warehouse for fact tables.
- Replication is where tables can be duplicated across all compute nodes - in a data warehouse the dimension tables could be replicated (duplicated) over every node.
MPP systems are not a silver bullet for all data storage / processing issues - for example highly transactions systems are likely to be better served by traditional RDBMS' which would run on an SMP.
For a more detailed overview here's a great introduction to PDW from Microsoft: Implementing Microsoft PDW